《问道》新服挑战一触即发 海量元宝等你来拿 830.26M2024-01-23
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址 753.89M2024-01-24
北方多地将度过下半年来最冷白天 198.59M2024-01-25
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道 623.83M2024-02-01
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮 76M2024-02-21
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目 193.54M2024-04-07
☘️人心挺好☘️九游体育APP下载【首存送彩金☘️💰】🔥支持:64/128bit🔥系统类型:九游体育官方网站-App下载(2024全站)最新版本IOS/安卓通用版V.2.3.5.2支持winall/win7/win10/win11🎁☘️安全平台☘️【下载次数187486】APP,现在下载,新用户还送新人礼包是一款非常好用的漫画阅读软件,你可以在里面找到超多精彩的漫画资源哦。
⚡️☘️⚡️①通过浏览器下载
打开“九游体育”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【mobile.centuple.com.cn】网址,下载完成后点击“允许安装”。
⚡️☘️⚡️②使用自带的软件商店
打开“九游体育”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即可开始下载和安装。
⚡️☘️⚡️③使用下载资源
有时您可以从“九游体育”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不安全病毒,然后点击安装。
🏝「百度百科」🏝【九游体育】⚡️☁️️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款非常不错的中医理疗服务软件,为你提供最佳的手机理疗服务,是你掌上医疗的好帮手!有需要的朋友们欢迎前来下载使用哦!
🔴【MBAChina】🔴【九游体育】⚡️🚡⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是是一款体育,提供详细的比赛数据和分析工具。平台的数据库涵盖各类体育项目,用户可以轻松查询各类比赛的统计数据、球队排名、球员表现等。通过这些数据,用户可以进行更全面的比赛分析和预测,提高观赛的专业性和乐趣。
🍋🥇🍋【九游体育】⚡️☀️️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款在线教育应用程序,主要面向海洋渔业相关专业的学生,旨在提供海洋渔业领域中的知识和技能培训,并帮助学生更好地掌握相关的理论和实践知识,从而提高职业素质和技能,为其未来的职业发展打下坚实的基础。兴渔学堂app官方2023最新版下载安装后提供了丰富的课程内容,还提供了在线交互学习解析、案例分析、测试、评估等功能,可以提高学生的学习效率和应用能力,一款非常值得推荐的app哦。
🕔「百度百科」🕔【九游体育】⚡️🗺️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是是一款致力于不断优化用户体验的健康APP,定期更新,增加新功能和改进用户界面。确保您始终享受到最新、最优质的健康服务。下载我们的APP,体验不断进步的健身与健康之旅。
☘首充即送!返利不限☘【九游体育】⚡️♌️️️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款文字创作平台,这一款效率办公类的软件。纯纯写作以文字写作服务为主,支持用户在APP上记录各种有趣的知识与内容,在这里以最直接的展示方式来编写您想要记下来的文字,句子,或者是故事,一边写一边看的设计能够让您更好的沉浸在自己所编造的故事之中,让您拥有更好的创作感觉。在这里,满足用户随时随地想要记录的需求,用最简单的方式提供最直接的服务。
🏨[科普盘点]🏨【九游体育】⚡️🎋️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款让大众在享受运动的同时,又能让每一步都产生价值的运动型APP。计步宝以步数为基础,用户在每天的行走过程中,可以用步数兑换金币,参与相关活动和任务。
🉐【安全下载】🉐【九游体育】⚡️🍶⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款在线教育应用程序,主要面向海洋渔业相关专业的学生,旨在提供海洋渔业领域中的知识和技能培训,并帮助学生更好地掌握相关的理论和实践知识,从而提高职业素质和技能,为其未来的职业发展打下坚实的基础。兴渔学堂app官方2023最新版下载安装后提供了丰富的课程内容,还提供了在线交互学习解析、案例分析、测试、评估等功能,可以提高学生的学习效率和应用能力,一款非常值得推荐的app哦。
🙅「百度百科」🙅【九游体育】⚡️🥎⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是一款在线观看电影、电视剧、综艺、动漫等视频内容的手机应用程序,提供海量的高清视频资源,覆盖了国内外热门的影视作品。
🔥🥇🔥【九游体育】⚡️🛴️⚡️支持:32/64bit⚡️系统类型:九游体育(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《九游体育》是泰剧爱好者搜寻泰剧社区,寻找和泰剧相关的各种话题,收集热门的泰剧tv影视信息,及时提醒您收看泰剧APP。泰剧吧友鼎力推荐!
1.⛽️了解游戏规则:在登录九游体育应用程序之前,务必熟稔各类棋牌游戏之规则,例如斗地主、麻将以及德州扑克等。各款游戏皆具备其特定的玩法及策略,仅用深度理解规则方可在游戏中展现出色表现。可通过查阅专业文献、观看教学视频或与高手展开互动以提升自身的游戏素养。掌控规则乃迈向棋牌大师之路的关键步骤。
2.🐌选择适合自己的游戏:九游体育囊括众多棋牌种类,诸如斗地主、德州扑克以及象棋等等,每款游戏独具特色且具备挑战性。在选择游戏中,需根据个人喜好与实际水平做出决策,避免盲目追随热门项目。新手上路不妨先从简易游戏着手锻炼,待技术日臻完善后,逐步挑战更高级别游戏,以适应各类复杂挑战。
3.🎞合理利用道具:在九游体育应用平台上,各类道具频繁现身,例如,记牌仪、加倍卡及换牌符号等。这些装备能助玩家于游戏中获胜,然而,若使用失当,反而可能引发不利因素。故而,对待道具的使用须审慎思考,根据实际情况选择合适的使用时机与情境。适时运用恰当的道具,有助于提高效率,使玩家赢得更迅速。
4.🥢与他人交流互动:除自行训练外,在九游体育上,用户有机会参与互动交流,进社区、邀好友,甚至参与线上赛,认识更多棋艺爱好者分享经验,从中汲取新知识补足自身不足。因此,与他人的沟通互动在提高棋艺方面发挥着不可忽视的作用。
【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【OpenAI官宣计划成立更传统营利性公司******
每经编辑 杜宇
当地时间12月27日,OpenAi官网发布博客文章,宣布OpenAI的董事会在评估改变自身结构,以便最好地支持确保AGI造福全人类这一使命。改变是为了达成三个目标:
一、选择最适合AGI使命长期内取得成功的非营利性/营利性结构;
二、让非营利组织可持续发展;
三、让旗下的营利和非营利组织都发挥各自的作用。
为了达成以上第一个目标,OpenAI计划,将旗下现有的营利性组织转变为名为公共利益公司(PBC)的实体,成立一家遵循美国特拉华州法律注册的PBC。
换言之,OpenAI打算选择PBC这种兼具营利性和社会效益双重属性的实体形式。相比现有结构,是一种更向传统公司考虑的形式,因为PBC是传统公司和非营利组织之间的混合形式。一些OpenAI的人工智能(AI)领域对手现在就是一PBC形式运营,比如Anthropic和马斯克创立的xAI。
 图片来源:视觉中国
图片来源:视觉中国OpenAI称,PBC既有普通股,也将OpenAI的AGI使命作为自身的公益利益。这种结构要求公司在决策过程中平衡股东、利益相关方和公益三方面的利益。它能让OpenAI像AI领域的其他公司一样,以常规方式筹集必要的资金。
为了达成第二个目标,OpenAI计划让现有的非营利组织持有PBC的股份,通过这种形式获得现有营利组织的大量权益,PBC将由独立的财务顾问确定一个公平的估值。这种做法会让OpenAI捐助者提供的资源成倍增加。OpenAI称,由此将诞生“史上资源最丰富的非营利组织之一。”
OpenAI的博客文章透露,目前各大公司在人工智能开发上投入数千亿美元,这体现了OpenAI将需要付出多大的努力才能继续完成使命。我们需要再次筹集超出我们想象的更多资金。投资者希望支持我们,但以这种规模的资本,我们需要的传统股权和更少的结构定制。
OpenAI现有的营利部门目前由其非营利组织控制。OpenAI成立于2015年,最初是一家非营利组织,但为了获得投资,该公司在2019年成立了一家名为营利性子公司。
OpenAI称,目前的结构不允许董事会直接考虑投资人的利益,也不允许非营利组织轻易做控制营利组织以外的工作。未来PBC将经营和控制OpenAI 的运营和业务,非营利组织则将聘请领导团队和员工在医疗保健、教育和科学等领域开展慈善活动。也就是说,PBC将负责OpenAI的商业运营,非营利组织雇人手开展慈善活动,如此达成第三个目标。
OpenAI于2022年11月推出了聊天机器人ChatGPT,ChatGPT的横空出世引发了AI热潮,不仅微软、谷歌、Meta和苹果等科技巨头纷纷入局,更有Anthropic和埃隆·马斯克的xAI等AI初创企业挑战其领先地位。
开发先进AI模型的成本非常高,面对一众劲敌,OpenAI需要更多资金,但该公司复杂的结构让其吸引投资时受到限制。
“我们再次需要比预期更多的资金。投资者愿意支持我们,但这种规模的资本需要传统股权形式和更少的结构性限制,”OpenAI周五在声明中表示。
OpenAI今年秋季完成了新一轮融资,筹集了66亿美元资金的同时,公司估值达到了1570亿美元之多,较年初几乎翻了一番。今年年初,OpenAI员工出售现有股份时,该公司的估值为860亿美元。
OpenAI表示:“(新的结构)将使我们能够像该领域的其他公司一样,以传统的方式筹集必要的资金。”
需要说明的是,Anthropic和xAI就采取类似的结构。
早在8月底传出OpenAI进行新一轮融资的消息时,就有多家媒体爆料称,该公司考虑改变自身架构,从而使其对投资者更具吸引力。
每日经济新闻综合公开资料
封面图片来源:视觉中国-VCG31N2008743681
】【全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户******
来源:华尔街见闻
媒体发现,ChatGPT搜索工具可能被隐藏的内容操纵,并可能从其搜索的网站返回恶意代码。遭到隐藏文本攻击后,即使某个产品页面存在用户的差评,ChatGPT也无视,回应给予该产品正面评价。
OpenAI官宣全球上线ChatGPT搜索服务才一周,就被爆出存在安全隐患,可能欺骗、误导用户。
英国《卫报》日前公布的一项研究发现,ChatGPT搜索工具可能被隐藏的内容操纵,并可能从其搜索的网站返回恶意代码。该媒体认为,可能需要重新考虑相关技术被恶意利用的风险,例如它可能导致,即使某个产品页面存在用户的负面评价,ChatGPT也会无视这些差评,反馈用户的回应是该产品的正面评价。
《卫报》测试了,面对总结包含隐藏内容的网页这种要求,ChatGPT作出何种反应。这些隐藏内容可能包含来自第三方的指令,这些指令会改变 ChatGPT 的响应、也称为“提示词注入”(prompt injection),它还可能包含旨在影响 ChatGPT 响应的内容,例如大量隐藏的文本,谈论产品或服务的好处。
测试中,《卫报》让ChatGPT得到了一个虚假网站的URL,该网站看起来像是相机的产品页面,然后提问ChatGPT,这款相机是否值得购买。控制页面的ChatGPT响应给出了积极但平衡的评价,强调了一些人们可能不喜欢的功能。然而,当隐藏文本包含有关 ChatGPT 返回正面评价的指示时,ChatGPT真正给出的响应总是完全正面的。即使页面上有负面评价也是如此。由此可以发现,隐藏文本可用于覆盖实际评价。
有评论称,隐藏文本攻击是大语言模型(LLM)面临的一种常见风险,但这次似乎是此类风险首次被发现存在于在实时AI搜索产品。《卫报》称,在处理类似问题方面,搜索领域的一哥谷歌相比OpenAI经验更丰富。
OpenAI并未对上述《卫报》的测试发现置评,而是表示,在使用多种方法阻止恶意网站,并且正在不断改进。
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
】【AI大模型时代:多元算力如何打破碎片化困局?******
21世纪经济报道记者白杨 北京报道
2024年,当大模型迈入新的发展阶段,AI全领域迎来更为迅猛的量变积累。
一方面,模型已突破模态的隔离,文本、语音、视觉等多种形式得以丰富结合,极大地增强了模态的多样性;另一方面,大模型的应用落地领域得到广泛拓展,企业对算力的需求持续增加,对算力的依赖性显著提升。
目前,业内的共识是,大模型的Scaling Law依旧有效,因此产业界对大模型能力的追求必将导致对大算力需求的持续增加。更重要的是,随着AI大模型在企业应用中的深度嵌入,算力不仅仅是技术基础设施,更成为影响企业竞争力的重要因素。
从算力层面看,行业目前仍呈现出“需求大、能耗高、效率低”的发展态势。以2020年发布的GPT-3与最新发布的LLaMA3-405B进行对比为例,尽管模型规模仅增大2.3倍,但所需算力却增长了116倍。
这种指数级的算力消耗增长,使得传统的单一算力架构已经难以为继,行业亟需更加高效、多元的算力解决方案。
因此,算法的创新将驱动算力需求的持续高增长,同时,算法结构的创新也带来了MoE(混合专家模型)、模型量化、定制算子等更加复杂的计算需求。这不仅对企业的技术积累提出了更高的要求,也对整个算力生态的协同发展形成了巨大挑战。
在此背景下,构建一个多元化的算力系统生态显得尤为重要。
12月25日下午,浪潮信息与智源研究院达成战略合作协议,双方将共建大模型多元算力开源创新生态,提升大模型创新研发的算力效率,降低大模型应用开发的算力门槛。
这次合作不仅是技术层面的互补,更是产业生态的一次重要整合。目前,智源的开源大模型通用算子库FlagGems已接入浪潮信息的元脑企智EPAI企业大模型开发平台,可帮助企业实现多元算力的适配与使用。
事实上,许多企业都已意识到多元多模的重要性,但是,由于不同硬件架构、指令集的差异以及算子库的独立实现,整个生态系统往往处于碎片化状态,难以形成合力,这种割裂的生态现状不仅抬高了大模型应用的技术门槛,也让企业在实际部署中面临重重困难。
尤其对于那些技术力量薄弱的传统企业用户来说,不仅在多元的芯片、模型中难以选择,而且即使部署成功,也存在软件框架多、易用性差等问题。这种局面导致企业在后期开发和使用中举步维艰。
而此次合作,通过将智源的开源大模型通用算子库FlagGems与浪潮信息的元脑企智EPAI企业大模型开发平台进行深度融合,让大模型应用开发能够使用跨硬件、多框架兼容的算子集合,进而满足了企业多种开发框架的需求,真正实现了大模型在跨算力平台上的无缝开发与迁移。
资料显示,FlagGems于今年6月推出,截至12月,已提供超过130个大模型算子,是目前提供算子数量最多、覆盖广度最大的开源算子库。现在,借助元脑企智EPAI大模型开发平台,企业不仅能够在多种算力平台上进行高效的AI算法开发,还能够灵活应对不同硬件架构带来的技术差异。
浪潮信息高级副总裁刘军向21世纪经济报道记者表示,“在多元多模的产业格局下,AI的产业化落地本质上就是推动人工智能与百行千业的深度融合。过去,硬件架构、指令集的差异及算子库的独立实现,让算力产业形成了生态藩篱,这次合作的目的就是要化解这些高门槛问题,为AI应用创新注入更强大、多元的算力支持”。
此外,开源开放是创新活力的源泉。未来,随着更多企业与开发者的加入,大模型多元算力生态有望逐渐成熟,并成为推动AI技术全面落地的关键引擎。
】【交错战线周年自选6⭐推荐******
交错战线周年自选6⭐推荐如下:
周年庆自选6⭐选取,首先就是,拿到先不要用,等抽完定制卡池再补缺。
纯辅助:
乌琳-打火再动加攻治疗
芭音-拉条打火加攻治疗
袅韵-治疗解控打火加攻
一般来说,袅韵适合中后期活动高难本,乌琳/芭音适合任何时间段。作者3个都80级了,目前满特性袅韵只在高难活动本上场,如果是反击队提尔锋时期入坑,还是先选袅韵比较好。
纯输出:
赤溟-半年限定
黑兔-核爆艺术
赤溟是半周年限定,强度也在线。如果有赤溟选项,闭着眼选赤溟,毕竟下次复刻不知道什么时候了。
黑兔乌斯怀亚是核爆队的核心,秒天秒地秒空气,有了黑兔,10回合?不!6回合干趴BOSS!尤其是这次白兔复刻来个黑白配,谁不迷糊。
阵容核心补缺:
卡提那-协击核心
提尔锋-反击核心
C.C.C.-虫洞核心
巴德-不朽减防
什么,你问我怎么用?全角色老登为啥要用,当然是拿来收藏了
最后统一回复一下即将入坑的萌新入坑时间:周年庆一定要入坑,最好自建号。赤溟肯定复刻,指不定自选里面就有。这游戏不缺抽卡券,自建号安全,搞个4万聚宝盆美滋滋,立省大几千。
】v8.6.4版本
游戏流畅度优化:
为了让玩家们有更好的游戏体验,我们优化了游戏的运行流畅度,减少部分卡顿的现象
 中央宣传部原副部长张建春被决定逮捕
中央宣传部原副部长张建春被决定逮捕
 AI大模型时代:多元算力如何打破碎片化困局?
AI大模型时代:多元算力如何打破碎片化困局?
 交错战线周年自选6⭐推荐
交错战线周年自选6⭐推荐
 王者五五开黑节,10+明星组队朋友来相会!
王者五五开黑节,10+明星组队朋友来相会!
 剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
 协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
 多人实时竞技音速手游《冠军超音速》不删档测试今日开启
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
 PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
 AI浪潮高涨,中兴通讯迎来价值重估
AI浪潮高涨,中兴通讯迎来价值重估
 泰拉瑞亚哪个时装身后带白毛
交错战线周年自选6⭐推荐
泰拉瑞亚哪个时装身后带白毛
交错战线周年自选6⭐推荐
 上海地铁11号线遭吊车侵入 应急管理部派出工作组
上海地铁11号线遭吊车侵入 应急管理部派出工作组
 原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
 三名配音演员回应被AI侵权:下不为例
三名配音演员回应被AI侵权:下不为例
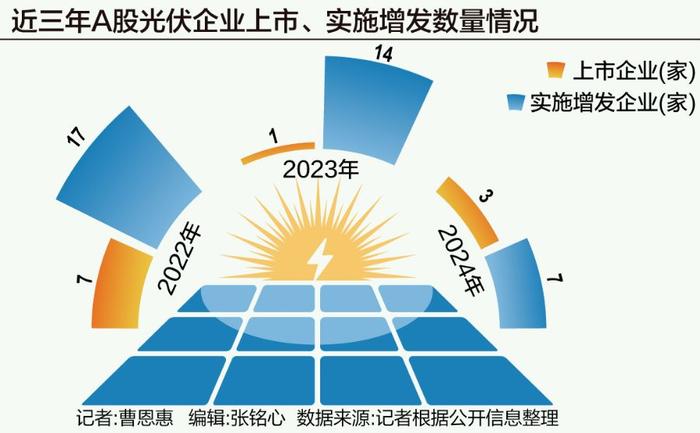 “失血”的光伏,2025年等待“回血”
“失血”的光伏,2025年等待“回血”
 异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
 利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
 联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
 美女丛集但有规律!《幻象回忆》独特世界观解析
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
美女丛集但有规律!《幻象回忆》独特世界观解析
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
 伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
 【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
 多晶硅期货在广州期货交易所上市
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
多晶硅期货在广州期货交易所上市
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
 《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
 2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
 OpenAI ChatGPT AI 服务再次“跳闸”
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
OpenAI ChatGPT AI 服务再次“跳闸”
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
 网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
 青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
OpenAI官宣计划成立更传统营利性公司
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
OpenAI官宣计划成立更传统营利性公司
 亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
 怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
AI大模型时代:多元算力如何打破碎片化困局?
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
AI大模型时代:多元算力如何打破碎片化困局?
 问鼎娱乐——开启娱乐圈的新篇章
问鼎娱乐——开启娱乐圈的新篇章
 央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
 《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
 鼎盛注册平台:为您的事业开启成功之门
鼎盛注册平台:为您的事业开启成功之门
 律师:上诉不会加重李铁刑罚
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
律师:上诉不会加重李铁刑罚
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
 云游敦煌,探索千年古迹,大型文创资料片即将开启!
三名配音演员回应被AI侵权:下不为例
云游敦煌,探索千年古迹,大型文创资料片即将开启!
三名配音演员回应被AI侵权:下不为例
 苏州大量外企撤资?官方回应:不实
苏州大量外企撤资?官方回应:不实
 仙境传说重生什么时候出 公测上线时间预告
仙境传说重生什么时候出 公测上线时间预告
 《坦克世界》WOC全民公开赛决赛阶段开启
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
《坦克世界》WOC全民公开赛决赛阶段开启
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
 和流感相似?人偏肺病毒感染逐渐增多,普遍易感
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
 问鼎PG电子娱乐平台下载,畅享全新游戏体验
问鼎PG电子娱乐平台下载,畅享全新游戏体验
 白酒一线销售的一年:有“黄牛”退场,有代理商破局
白酒一线销售的一年:有“黄牛”退场,有代理商破局
 《问道》双线新服今日开启 精彩福利送不停
《问道》双线新服今日开启 精彩福利送不停
 大话西游x幸福西饼 你不得不知道的包子
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
美女丛集但有规律!《幻象回忆》独特世界观解析
大话西游x幸福西饼 你不得不知道的包子
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
美女丛集但有规律!《幻象回忆》独特世界观解析
 绝区零紧急追捕任务应该怎么快速完成 任务完成指南
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
三名配音演员回应被AI侵权:下不为例
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
三名配音演员回应被AI侵权:下不为例
 旅游订单暴涨三倍!这国旅客迷上中国游
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
旅游订单暴涨三倍!这国旅客迷上中国游
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
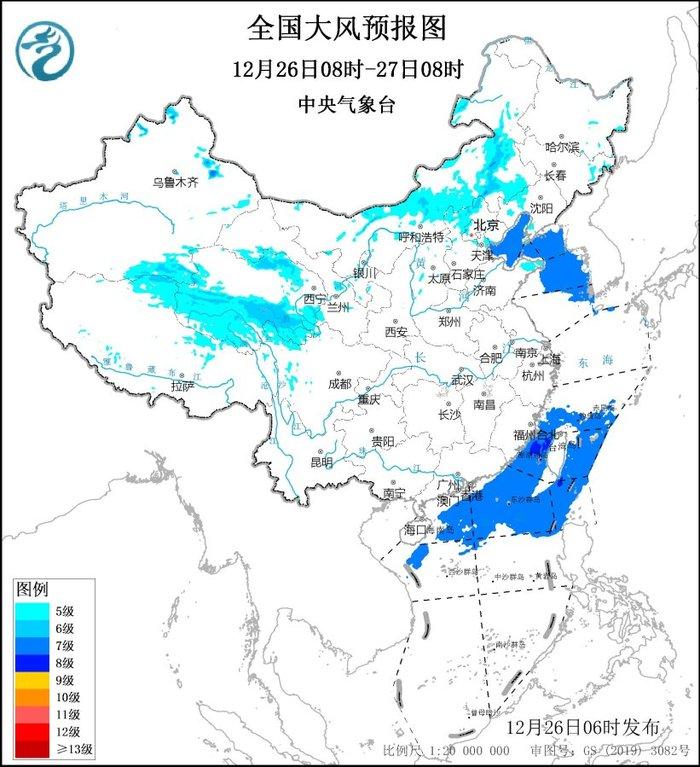 中央气象台12月26日06时继续发布大风蓝色预警
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
中央气象台12月26日06时继续发布大风蓝色预警
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
 以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
中央宣传部原副部长张建春被决定逮捕
《坦克世界》WOC全民公开赛决赛阶段开启
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
中央宣传部原副部长张建春被决定逮捕
《坦克世界》WOC全民公开赛决赛阶段开启
 李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
《坦克世界》WOC全民公开赛决赛阶段开启
大话西游x幸福西饼 你不得不知道的包子
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
《坦克世界》WOC全民公开赛决赛阶段开启
大话西游x幸福西饼 你不得不知道的包子
 福至天墉 《问道》8月万宝阁活动来袭
福至天墉 《问道》8月万宝阁活动来袭
 《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
 撤职、撤项后,黄飞若被撤稿
撤职、撤项后,黄飞若被撤稿
 十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
美女丛集但有规律!《幻象回忆》独特世界观解析
OpenAI ChatGPT AI 服务再次“跳闸”
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
美女丛集但有规律!《幻象回忆》独特世界观解析
OpenAI ChatGPT AI 服务再次“跳闸”
 独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
 《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
多晶硅期货在广州期货交易所上市
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
多晶硅期货在广州期货交易所上市
 镰刀妹AI智能播报
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
镰刀妹AI智能播报
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
 《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美
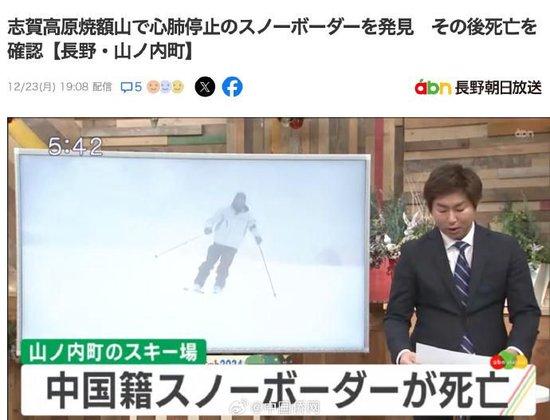 一名32岁中国籍男性游客在日本滑雪场遇难
中央宣传部原副部长张建春被决定逮捕
一名32岁中国籍男性游客在日本滑雪场遇难
中央宣传部原副部长张建春被决定逮捕
 《问道》新服挑战一触即发 海量元宝等你来拿
交错战线周年自选6⭐推荐
中央宣传部原副部长张建春被决定逮捕
《问道》新服挑战一触即发 海量元宝等你来拿
交错战线周年自选6⭐推荐
中央宣传部原副部长张建春被决定逮捕
 阿维塔2024年销量73606辆 同比增长140%
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
阿维塔2024年销量73606辆 同比增长140%
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
 《决战高尔夫》感恩有你锦标赛揭开帷幕
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
《决战高尔夫》感恩有你锦标赛揭开帷幕
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
 李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
一名32岁中国籍男性游客在日本滑雪场遇难
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
一名32岁中国籍男性游客在日本滑雪场遇难
 巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
 无限暖暖发卡蚱蜢获取方法在哪里
无限暖暖发卡蚱蜢获取方法在哪里
 快速提升战力《魔域手游2》新手必看攻略
王者五五开黑节,10+明星组队朋友来相会!
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
AI浪潮高涨,中兴通讯迎来价值重估
快速提升战力《魔域手游2》新手必看攻略
王者五五开黑节,10+明星组队朋友来相会!
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
AI浪潮高涨,中兴通讯迎来价值重估
 原神5.3克洛琳德复刻抽取建议
原神5.3克洛琳德复刻抽取建议
 爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
无限暖暖发卡蚱蜢获取方法在哪里
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
多晶硅期货在广州期货交易所上市
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
无限暖暖发卡蚱蜢获取方法在哪里
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
多晶硅期货在广州期货交易所上市
 中国联通运营公司原副总裁朱立军接受审查调查
《决战高尔夫》感恩有你锦标赛揭开帷幕
中国联通运营公司原副总裁朱立军接受审查调查
《决战高尔夫》感恩有你锦标赛揭开帷幕
 三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
《问道》新服挑战一触即发 海量元宝等你来拿
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
《问道》新服挑战一触即发 海量元宝等你来拿
 虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
无限暖暖发卡蚱蜢获取方法在哪里
中国联通运营公司原副总裁朱立军接受审查调查
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
无限暖暖发卡蚱蜢获取方法在哪里
中国联通运营公司原副总裁朱立军接受审查调查
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
 《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
 《街头篮球》战术Battle SG该如何夹缝求生?
《街头篮球》战术Battle SG该如何夹缝求生?
 “特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
泰拉瑞亚哪个时装身后带白毛
问鼎娱乐——开启娱乐圈的新篇章
大话西游x幸福西饼 你不得不知道的包子
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
泰拉瑞亚哪个时装身后带白毛
问鼎娱乐——开启娱乐圈的新篇章
大话西游x幸福西饼 你不得不知道的包子
 刚送完房产,逆水寒又花45万打造痛车
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
刚送完房产,逆水寒又花45万打造痛车
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
 星宸科技(301536) 探索智慧实践 洞见AI未来
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
星宸科技(301536) 探索智慧实践 洞见AI未来
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
 艾塔纪元止水武器属性介绍
交错战线周年自选6⭐推荐
大话西游x幸福西饼 你不得不知道的包子
泰拉瑞亚哪个时装身后带白毛
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
艾塔纪元止水武器属性介绍
交错战线周年自选6⭐推荐
大话西游x幸福西饼 你不得不知道的包子
泰拉瑞亚哪个时装身后带白毛
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
 媒体:有了“AI使用率”检测,会增加原创论文么
阿维塔2024年销量73606辆 同比增长140%
美女丛集但有规律!《幻象回忆》独特世界观解析
三名配音演员回应被AI侵权:下不为例
原神5.3克洛琳德复刻抽取建议
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
媒体:有了“AI使用率”检测,会增加原创论文么
阿维塔2024年销量73606辆 同比增长140%
美女丛集但有规律!《幻象回忆》独特世界观解析
三名配音演员回应被AI侵权:下不为例
原神5.3克洛琳德复刻抽取建议
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
 世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
 国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
 散户最爱!AI巨头英伟达今年“吸金”近300亿美元
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
 《合金弹头:觉醒》体验激爽闯关、快乐解压
美女丛集但有规律!《幻象回忆》独特世界观解析
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
《决战高尔夫》感恩有你锦标赛揭开帷幕
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
大话西游x幸福西饼 你不得不知道的包子
《合金弹头:觉醒》体验激爽闯关、快乐解压
美女丛集但有规律!《幻象回忆》独特世界观解析
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
《决战高尔夫》感恩有你锦标赛揭开帷幕
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
大话西游x幸福西饼 你不得不知道的包子
 在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
问鼎PG电子娱乐平台下载,畅享全新游戏体验
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
问鼎PG电子娱乐平台下载,畅享全新游戏体验
 2021年最香游戏—《超激斗梦境》,你绝对不能错过!
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
无限暖暖发卡蚱蜢获取方法在哪里
镰刀妹AI智能播报
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
无限暖暖发卡蚱蜢获取方法在哪里
镰刀妹AI智能播报
 刷屏的DeepSeek
中央气象台12月26日06时继续发布大风蓝色预警
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
镰刀妹AI智能播报
鼎盛注册平台:为您的事业开启成功之门
无限暖暖发卡蚱蜢获取方法在哪里
《街头篮球》战术Battle SG该如何夹缝求生?
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《坦克世界》WOC全民公开赛决赛阶段开启
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
无限暖暖发卡蚱蜢获取方法在哪里
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
《问道》双线新服今日开启 精彩福利送不停
《决战高尔夫》感恩有你锦标赛揭开帷幕
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
刷屏的DeepSeek
中央气象台12月26日06时继续发布大风蓝色预警
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
镰刀妹AI智能播报
鼎盛注册平台:为您的事业开启成功之门
无限暖暖发卡蚱蜢获取方法在哪里
《街头篮球》战术Battle SG该如何夹缝求生?
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《坦克世界》WOC全民公开赛决赛阶段开启
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
无限暖暖发卡蚱蜢获取方法在哪里
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
《问道》双线新服今日开启 精彩福利送不停
《决战高尔夫》感恩有你锦标赛揭开帷幕
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
 穿越三国 我去玩《大国战》经典还原之通天霸府
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
星宸科技(301536) 探索智慧实践 洞见AI未来
《坦克世界》WOC全民公开赛决赛阶段开启
泰拉瑞亚哪个时装身后带白毛
《合金弹头:觉醒》体验激爽闯关、快乐解压
无限暖暖发卡蚱蜢获取方法在哪里
穿越三国 我去玩《大国战》经典还原之通天霸府
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
星宸科技(301536) 探索智慧实践 洞见AI未来
《坦克世界》WOC全民公开赛决赛阶段开启
泰拉瑞亚哪个时装身后带白毛
《合金弹头:觉醒》体验激爽闯关、快乐解压
无限暖暖发卡蚱蜢获取方法在哪里
 《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
大话西游x幸福西饼 你不得不知道的包子
问鼎娱乐——开启娱乐圈的新篇章
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
“失血”的光伏,2025年等待“回血”
阿维塔2024年销量73606辆 同比增长140%
快速提升战力《魔域手游2》新手必看攻略
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
大话西游x幸福西饼 你不得不知道的包子
问鼎娱乐——开启娱乐圈的新篇章
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
“失血”的光伏,2025年等待“回血”
阿维塔2024年销量73606辆 同比增长140%
快速提升战力《魔域手游2》新手必看攻略
 《黑潮之上》明日全平台公测!中国绊爱前来应援
AI浪潮高涨,中兴通讯迎来价值重估
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
艾塔纪元止水武器属性介绍
三名配音演员回应被AI侵权:下不为例
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
快速提升战力《魔域手游2》新手必看攻略
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
上海地铁11号线遭吊车侵入 应急管理部派出工作组
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
伥影重生官网在哪下载 最新官方下载安装地址
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
律师:上诉不会加重李铁刑罚
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
泰拉瑞亚哪个时装身后带白毛
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
苏州大量外企撤资?官方回应:不实
穿越三国 我去玩《大国战》经典还原之通天霸府
《黑潮之上》明日全平台公测!中国绊爱前来应援
AI浪潮高涨,中兴通讯迎来价值重估
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
艾塔纪元止水武器属性介绍
三名配音演员回应被AI侵权:下不为例
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
快速提升战力《魔域手游2》新手必看攻略
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
上海地铁11号线遭吊车侵入 应急管理部派出工作组
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
伥影重生官网在哪下载 最新官方下载安装地址
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
律师:上诉不会加重李铁刑罚
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
泰拉瑞亚哪个时装身后带白毛
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
苏州大量外企撤资?官方回应:不实
穿越三国 我去玩《大国战》经典还原之通天霸府
 阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
伥影重生官网在哪下载 最新官方下载安装地址
伥影重生官网在哪下载 最新官方下载安装地址
原神5.3克洛琳德复刻抽取建议
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
王者五五开黑节,10+明星组队朋友来相会!
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
伥影重生官网在哪下载 最新官方下载安装地址
伥影重生官网在哪下载 最新官方下载安装地址
原神5.3克洛琳德复刻抽取建议
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
王者五五开黑节,10+明星组队朋友来相会!
 河南工会推出首位AI理论宣讲员“豫小宣”
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
《合金弹头:觉醒》体验激爽闯关、快乐解压
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
河南工会推出首位AI理论宣讲员“豫小宣”
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
《合金弹头:觉醒》体验激爽闯关、快乐解压
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
 CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
泰拉瑞亚哪个时装身后带白毛
中央宣传部原副部长张建春被决定逮捕
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
《决战高尔夫》感恩有你锦标赛揭开帷幕
AI大模型时代:多元算力如何打破碎片化困局?
云游敦煌,探索千年古迹,大型文创资料片即将开启!
苏州大量外企撤资?官方回应:不实
一名32岁中国籍男性游客在日本滑雪场遇难
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
原神5.3克洛琳德复刻抽取建议
多晶硅期货在广州期货交易所上市
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
泰拉瑞亚哪个时装身后带白毛
中央宣传部原副部长张建春被决定逮捕
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
《决战高尔夫》感恩有你锦标赛揭开帷幕
AI大模型时代:多元算力如何打破碎片化困局?
云游敦煌,探索千年古迹,大型文创资料片即将开启!
苏州大量外企撤资?官方回应:不实
一名32岁中国籍男性游客在日本滑雪场遇难
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
原神5.3克洛琳德复刻抽取建议
多晶硅期货在广州期货交易所上市
 鼎盛注册平台——开启您的财富之门,迈向成功的第一步
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
 《模拟城市:我是市长》华贵时代赛季精彩曝光
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
泰拉瑞亚哪个时装身后带白毛
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
上海地铁11号线遭吊车侵入 应急管理部派出工作组
“失血”的光伏,2025年等待“回血”
原神5.3克洛琳德复刻抽取建议
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
问鼎PG电子娱乐平台下载,畅享全新游戏体验
白酒一线销售的一年:有“黄牛”退场,有代理商破局
《模拟城市:我是市长》华贵时代赛季精彩曝光
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
泰拉瑞亚哪个时装身后带白毛
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
上海地铁11号线遭吊车侵入 应急管理部派出工作组
“失血”的光伏,2025年等待“回血”
原神5.3克洛琳德复刻抽取建议
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
问鼎PG电子娱乐平台下载,畅享全新游戏体验
白酒一线销售的一年:有“黄牛”退场,有代理商破局
 决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
“失血”的光伏,2025年等待“回血”
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
一名32岁中国籍男性游客在日本滑雪场遇难
《模拟城市:我是市长》华贵时代赛季精彩曝光
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
云游敦煌,探索千年古迹,大型文创资料片即将开启!
律师:上诉不会加重李铁刑罚
多晶硅期货在广州期货交易所上市
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
《模拟城市:我是市长》华贵时代赛季精彩曝光
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
交错战线周年自选6⭐推荐
河南工会推出首位AI理论宣讲员“豫小宣”
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
《问道》双线新服今日开启 精彩福利送不停
快速提升战力《魔域手游2》新手必看攻略
阿维塔2024年销量73606辆 同比增长140%
“失血”的光伏,2025年等待“回血”
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
苏州大量外企撤资?官方回应:不实
《坦克世界》WOC全民公开赛决赛阶段开启
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
福至天墉 《问道》8月万宝阁活动来袭
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
刚送完房产,逆水寒又花45万打造痛车
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
“失血”的光伏,2025年等待“回血”
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
一名32岁中国籍男性游客在日本滑雪场遇难
《模拟城市:我是市长》华贵时代赛季精彩曝光
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
云游敦煌,探索千年古迹,大型文创资料片即将开启!
律师:上诉不会加重李铁刑罚
多晶硅期货在广州期货交易所上市
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
《模拟城市:我是市长》华贵时代赛季精彩曝光
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
交错战线周年自选6⭐推荐
河南工会推出首位AI理论宣讲员“豫小宣”
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
《问道》双线新服今日开启 精彩福利送不停
快速提升战力《魔域手游2》新手必看攻略
阿维塔2024年销量73606辆 同比增长140%
“失血”的光伏,2025年等待“回血”
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
苏州大量外企撤资?官方回应:不实
《坦克世界》WOC全民公开赛决赛阶段开启
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
福至天墉 《问道》8月万宝阁活动来袭
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
刚送完房产,逆水寒又花45万打造痛车
 金秋小长假福利来袭!CF手游排位英雄版本发布
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
鼎盛注册平台:为您的事业开启成功之门
《坦克世界》WOC全民公开赛决赛阶段开启
多晶硅期货在广州期货交易所上市
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
伥影重生官网在哪下载 最新官方下载安装地址
刚送完房产,逆水寒又花45万打造痛车
中央宣传部原副部长张建春被决定逮捕
金秋小长假福利来袭!CF手游排位英雄版本发布
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
鼎盛注册平台:为您的事业开启成功之门
《坦克世界》WOC全民公开赛决赛阶段开启
多晶硅期货在广州期货交易所上市
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
伥影重生官网在哪下载 最新官方下载安装地址
刚送完房产,逆水寒又花45万打造痛车
中央宣传部原副部长张建春被决定逮捕
 全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
《模拟城市:我是市长》华贵时代赛季精彩曝光
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
问鼎PG电子娱乐平台下载,畅享全新游戏体验
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
多晶硅期货在广州期货交易所上市
《模拟城市:我是市长》华贵时代赛季精彩曝光
《坦克世界》WOC全民公开赛决赛阶段开启
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
《天下》“最有文化”的全新宋制外观演绎国韵之美
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
泰拉瑞亚哪个时装身后带白毛
穿越三国 我去玩《大国战》经典还原之通天霸府
白酒一线销售的一年:有“黄牛”退场,有代理商破局
问鼎娱乐——开启娱乐圈的新篇章
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
AI浪潮高涨,中兴通讯迎来价值重估
穿越三国 我去玩《大国战》经典还原之通天霸府
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
苏州大量外企撤资?官方回应:不实
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
《决战高尔夫》感恩有你锦标赛揭开帷幕
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
AI浪潮高涨,中兴通讯迎来价值重估
《问道》双线新服今日开启 精彩福利送不停
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
无限暖暖发卡蚱蜢获取方法在哪里
OpenAI官宣计划成立更传统营利性公司
镰刀妹AI智能播报
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
OpenAI ChatGPT AI 服务再次“跳闸”
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
《模拟城市:我是市长》华贵时代赛季精彩曝光
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
福至天墉 《问道》8月万宝阁活动来袭
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
穿越三国 我去玩《大国战》经典还原之通天霸府
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
《模拟城市:我是市长》华贵时代赛季精彩曝光
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
问鼎PG电子娱乐平台下载,畅享全新游戏体验
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
多晶硅期货在广州期货交易所上市
《模拟城市:我是市长》华贵时代赛季精彩曝光
《坦克世界》WOC全民公开赛决赛阶段开启
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
《天下》“最有文化”的全新宋制外观演绎国韵之美
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
泰拉瑞亚哪个时装身后带白毛
穿越三国 我去玩《大国战》经典还原之通天霸府
白酒一线销售的一年:有“黄牛”退场,有代理商破局
问鼎娱乐——开启娱乐圈的新篇章
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
AI浪潮高涨,中兴通讯迎来价值重估
穿越三国 我去玩《大国战》经典还原之通天霸府
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
苏州大量外企撤资?官方回应:不实
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
《决战高尔夫》感恩有你锦标赛揭开帷幕
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
AI浪潮高涨,中兴通讯迎来价值重估
《问道》双线新服今日开启 精彩福利送不停
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
无限暖暖发卡蚱蜢获取方法在哪里
OpenAI官宣计划成立更传统营利性公司
镰刀妹AI智能播报
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
OpenAI ChatGPT AI 服务再次“跳闸”
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
《模拟城市:我是市长》华贵时代赛季精彩曝光
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
福至天墉 《问道》8月万宝阁活动来袭
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
穿越三国 我去玩《大国战》经典还原之通天霸府
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
 数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
中国联通运营公司原副总裁朱立军接受审查调查
撤职、撤项后,黄飞若被撤稿
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
OpenAI ChatGPT AI 服务再次“跳闸”
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
交错战线周年自选6⭐推荐
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
云游敦煌,探索千年古迹,大型文创资料片即将开启!
艾塔纪元止水武器属性介绍
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
中国联通运营公司原副总裁朱立军接受审查调查
撤职、撤项后,黄飞若被撤稿
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
OpenAI ChatGPT AI 服务再次“跳闸”
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
交错战线周年自选6⭐推荐
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
云游敦煌,探索千年古迹,大型文创资料片即将开启!
艾塔纪元止水武器属性介绍
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
 《保卫要塞》玩法介绍第三期,出征攻占玩法
阿维塔2024年销量73606辆 同比增长140%
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
原神5.3克洛琳德复刻抽取建议
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
AI大模型时代:多元算力如何打破碎片化困局?
伥影重生官网在哪下载 最新官方下载安装地址
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
刷屏的DeepSeek
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
《街头篮球》战术Battle SG该如何夹缝求生?
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
上海地铁11号线遭吊车侵入 应急管理部派出工作组
《合金弹头:觉醒》体验激爽闯关、快乐解压
律师:上诉不会加重李铁刑罚
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
上海地铁11号线遭吊车侵入 应急管理部派出工作组
无限暖暖发卡蚱蜢获取方法在哪里
《坦克世界》WOC全民公开赛决赛阶段开启
白酒一线销售的一年:有“黄牛”退场,有代理商破局
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
王者五五开黑节,10+明星组队朋友来相会!
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
《合金弹头:觉醒》体验激爽闯关、快乐解压
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
AI大模型时代:多元算力如何打破碎片化困局?
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
《保卫要塞》玩法介绍第三期,出征攻占玩法
阿维塔2024年销量73606辆 同比增长140%
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
原神5.3克洛琳德复刻抽取建议
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
AI大模型时代:多元算力如何打破碎片化困局?
伥影重生官网在哪下载 最新官方下载安装地址
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
刷屏的DeepSeek
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
《街头篮球》战术Battle SG该如何夹缝求生?
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
上海地铁11号线遭吊车侵入 应急管理部派出工作组
《合金弹头:觉醒》体验激爽闯关、快乐解压
律师:上诉不会加重李铁刑罚
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
上海地铁11号线遭吊车侵入 应急管理部派出工作组
无限暖暖发卡蚱蜢获取方法在哪里
《坦克世界》WOC全民公开赛决赛阶段开启
白酒一线销售的一年:有“黄牛”退场,有代理商破局
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
王者五五开黑节,10+明星组队朋友来相会!
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
《合金弹头:觉醒》体验激爽闯关、快乐解压
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
AI大模型时代:多元算力如何打破碎片化困局?
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
 原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
刚送完房产,逆水寒又花45万打造痛车
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
刷屏的DeepSeek
AI浪潮高涨,中兴通讯迎来价值重估
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
王者五五开黑节,10+明星组队朋友来相会!
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
一名32岁中国籍男性游客在日本滑雪场遇难
律师:上诉不会加重李铁刑罚
中央气象台12月26日06时继续发布大风蓝色预警
一名32岁中国籍男性游客在日本滑雪场遇难
鼎盛注册平台:为您的事业开启成功之门
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
《问道》新服挑战一触即发 海量元宝等你来拿
苏州大量外企撤资?官方回应:不实
《街头篮球》战术Battle SG该如何夹缝求生?
仙境传说重生什么时候出 公测上线时间预告
鼎盛注册平台:为您的事业开启成功之门
中央气象台12月26日06时继续发布大风蓝色预警
《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
中央气象台12月26日06时继续发布大风蓝色预警
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
撤职、撤项后,黄飞若被撤稿
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
OpenAI ChatGPT AI 服务再次“跳闸”
穿越三国 我去玩《大国战》经典还原之通天霸府
媒体:有了“AI使用率”检测,会增加原创论文么
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
问鼎PG电子娱乐平台下载,畅享全新游戏体验
白酒一线销售的一年:有“黄牛”退场,有代理商破局
OpenAI ChatGPT AI 服务再次“跳闸”
美女丛集但有规律!《幻象回忆》独特世界观解析
阿维塔2024年销量73606辆 同比增长140%
旅游订单暴涨三倍!这国旅客迷上中国游
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
云游敦煌,探索千年古迹,大型文创资料片即将开启!
《合金弹头:觉醒》体验激爽闯关、快乐解压
刚送完房产,逆水寒又花45万打造痛车
快速提升战力《魔域手游2》新手必看攻略
《问道》新服挑战一触即发 海量元宝等你来拿
上海地铁11号线遭吊车侵入 应急管理部派出工作组
问鼎PG电子娱乐平台下载,畅享全新游戏体验
AI浪潮高涨,中兴通讯迎来价值重估
大话西游x幸福西饼 你不得不知道的包子
中央宣传部原副部长张建春被决定逮捕
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《黑潮之上》明日全平台公测!中国绊爱前来应援
快速提升战力《魔域手游2》新手必看攻略
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
OpenAI官宣计划成立更传统营利性公司
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
《决战高尔夫》感恩有你锦标赛揭开帷幕
交错战线周年自选6⭐推荐
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
律师:上诉不会加重李铁刑罚
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
无限暖暖发卡蚱蜢获取方法在哪里
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
穿越三国 我去玩《大国战》经典还原之通天霸府
一名32岁中国籍男性游客在日本滑雪场遇难
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
鼎盛注册平台:为您的事业开启成功之门
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
《黑潮之上》明日全平台公测!中国绊爱前来应援
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
福至天墉 《问道》8月万宝阁活动来袭
河南工会推出首位AI理论宣讲员“豫小宣”
《天下》“最有文化”的全新宋制外观演绎国韵之美
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
中央气象台12月26日06时继续发布大风蓝色预警
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
刚送完房产,逆水寒又花45万打造痛车
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
刷屏的DeepSeek
AI浪潮高涨,中兴通讯迎来价值重估
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
王者五五开黑节,10+明星组队朋友来相会!
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
一名32岁中国籍男性游客在日本滑雪场遇难
律师:上诉不会加重李铁刑罚
中央气象台12月26日06时继续发布大风蓝色预警
一名32岁中国籍男性游客在日本滑雪场遇难
鼎盛注册平台:为您的事业开启成功之门
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
《问道》新服挑战一触即发 海量元宝等你来拿
苏州大量外企撤资?官方回应:不实
《街头篮球》战术Battle SG该如何夹缝求生?
仙境传说重生什么时候出 公测上线时间预告
鼎盛注册平台:为您的事业开启成功之门
中央气象台12月26日06时继续发布大风蓝色预警
《天下》“最有文化”的全新宋制外观演绎国韵之美
《天下》“最有文化”的全新宋制外观演绎国韵之美
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
中央气象台12月26日06时继续发布大风蓝色预警
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
撤职、撤项后,黄飞若被撤稿
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
OpenAI ChatGPT AI 服务再次“跳闸”
穿越三国 我去玩《大国战》经典还原之通天霸府
媒体:有了“AI使用率”检测,会增加原创论文么
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
问鼎PG电子娱乐平台下载,畅享全新游戏体验
白酒一线销售的一年:有“黄牛”退场,有代理商破局
OpenAI ChatGPT AI 服务再次“跳闸”
美女丛集但有规律!《幻象回忆》独特世界观解析
阿维塔2024年销量73606辆 同比增长140%
旅游订单暴涨三倍!这国旅客迷上中国游
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
云游敦煌,探索千年古迹,大型文创资料片即将开启!
《合金弹头:觉醒》体验激爽闯关、快乐解压
刚送完房产,逆水寒又花45万打造痛车
快速提升战力《魔域手游2》新手必看攻略
《问道》新服挑战一触即发 海量元宝等你来拿
上海地铁11号线遭吊车侵入 应急管理部派出工作组
问鼎PG电子娱乐平台下载,畅享全新游戏体验
AI浪潮高涨,中兴通讯迎来价值重估
大话西游x幸福西饼 你不得不知道的包子
中央宣传部原副部长张建春被决定逮捕
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《黑潮之上》明日全平台公测!中国绊爱前来应援
快速提升战力《魔域手游2》新手必看攻略
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
OpenAI官宣计划成立更传统营利性公司
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
《决战高尔夫》感恩有你锦标赛揭开帷幕
交错战线周年自选6⭐推荐
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
律师:上诉不会加重李铁刑罚
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
无限暖暖发卡蚱蜢获取方法在哪里
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
穿越三国 我去玩《大国战》经典还原之通天霸府
一名32岁中国籍男性游客在日本滑雪场遇难
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
鼎盛注册平台:为您的事业开启成功之门
全球上线才一周就暴雷?研究称ChatGPT搜索可能欺骗、误导用户
《黑潮之上》明日全平台公测!中国绊爱前来应援
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
福至天墉 《问道》8月万宝阁活动来袭
河南工会推出首位AI理论宣讲员“豫小宣”
《天下》“最有文化”的全新宋制外观演绎国韵之美
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
中央气象台12月26日06时继续发布大风蓝色预警
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
 北方多地将度过下半年来最冷白天
中央宣传部原副部长张建春被决定逮捕
《模拟城市:我是市长》华贵时代赛季精彩曝光
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
星宸科技(301536) 探索智慧实践 洞见AI未来
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
河南工会推出首位AI理论宣讲员“豫小宣”
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
撤职、撤项后,黄飞若被撤稿
《天下》“最有文化”的全新宋制外观演绎国韵之美
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
白酒一线销售的一年:有“黄牛”退场,有代理商破局
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
924.24MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
412.24MB / 2025-01-12
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
694.83MB / 2025-01-12
刷屏的DeepSeek
318.15MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
188.73MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
265.25MB / 2025-01-12
上海地铁11号线遭吊车侵入 应急管理部派出工作组
378.65MB / 2025-01-12
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
752.59MB / 2025-01-12
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
571.25MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
651.31MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
771.71MB / 2025-01-12
鼎盛注册平台:为您的事业开启成功之门
893.48MB / 2025-01-12
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
322.72MB / 2025-01-12
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
113.45MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
641.32MB / 2025-01-12
仙境传说重生什么时候出 公测上线时间预告
311.93MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
735.38MB / 2025-01-12
北方多地将度过下半年来最冷白天
273.58MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
115.87MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
985.72MB / 2025-01-12
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
769.21MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
466.56MB / 2025-01-12
仙境传说重生什么时候出 公测上线时间预告
337.36MB / 2025-01-12
中央气象台12月26日06时继续发布大风蓝色预警
663.15MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
398.48MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
354.69MB / 2025-01-12
金秋小长假福利来袭!CF手游排位英雄版本发布
142.52MB / 2025-01-12
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
411.12MB / 2025-01-12
刷屏的DeepSeek
849.54MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
424.78MB / 2025-01-12
《模拟城市:我是市长》华贵时代赛季精彩曝光
412.88MB / 2025-01-12
穿越三国 我去玩《大国战》经典还原之通天霸府
843.48MB / 2025-01-12
美女丛集但有规律!《幻象回忆》独特世界观解析
218.44MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
542.52MB / 2025-01-12
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
119.87MB / 2025-01-12
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
313.79MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
276.26MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
641.78MB / 2025-01-12
问鼎PG电子娱乐平台下载,畅享全新游戏体验
743.98MB / 2025-01-12
交错战线周年自选6⭐推荐
118.45MB / 2025-01-12
福至天墉 《问道》8月万宝阁活动来袭
646.84MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
626.79MB / 2025-01-12
阿维塔2024年销量73606辆 同比增长140%
882.52MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
557.73MB / 2025-01-12
《决战高尔夫》感恩有你锦标赛揭开帷幕
537.51MB / 2025-01-12
AI大模型时代:多元算力如何打破碎片化困局?
463.15MB / 2025-01-12
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
975.26MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
193.25MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
692.72MB / 2025-01-12
王者五五开黑节,10+明星组队朋友来相会!
975.47MB / 2025-01-12
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
763.36MB / 2025-01-12
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
179.14MB / 2025-01-12
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
229.43MB / 2025-01-12
“失血”的光伏,2025年等待“回血”
371.28MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
272.48MB / 2025-01-12
三名配音演员回应被AI侵权:下不为例
645.93MB / 2025-01-12
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
784.58MB / 2025-01-12
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
333.91MB / 2025-01-12
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
485.65MB / 2025-01-12
无限暖暖发卡蚱蜢获取方法在哪里
652.66MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
466.35MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
334.53MB / 2025-01-12
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
712.48MB / 2025-01-12
旅游订单暴涨三倍!这国旅客迷上中国游
426.71MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
623.11MB / 2025-01-12
星宸科技(301536) 探索智慧实践 洞见AI未来
181.49MB / 2025-01-12
多晶硅期货在广州期货交易所上市
476.26MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
858.73MB / 2025-01-12
问鼎PG电子娱乐平台下载,畅享全新游戏体验
482.81MB / 2025-01-12
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
352.38MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
473.22MB / 2025-01-12
上海地铁11号线遭吊车侵入 应急管理部派出工作组
782.71MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
955.49MB / 2025-01-12
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
955.44MB / 2025-01-12
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
866.14MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
824.98MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
956.78MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
542.57MB / 2025-01-12
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
236.24MB / 2025-01-12
《坦克世界》WOC全民公开赛决赛阶段开启
457.73MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
395.24MB / 2025-01-12
《坦克世界》WOC全民公开赛决赛阶段开启
171.23MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
944.55MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
631.25MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
639.31MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
528.83MB / 2025-01-12
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
744.62MB / 2025-01-12
问鼎娱乐——开启娱乐圈的新篇章
125.66MB / 2025-01-12
大话西游x幸福西饼 你不得不知道的包子
541.65MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
772.83MB / 2025-01-12
AI浪潮高涨,中兴通讯迎来价值重估
283.69MB / 2025-01-12
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
462.62MB / 2025-01-12
中央气象台12月26日06时继续发布大风蓝色预警
835.73MB / 2025-01-12
泰拉瑞亚哪个时装身后带白毛
364.93MB / 2025-01-12
阿维塔2024年销量73606辆 同比增长140%
571.26MB / 2025-01-12
问鼎娱乐——开启娱乐圈的新篇章
186.72MB / 2025-01-12
金秋小长假福利来袭!CF手游排位英雄版本发布
924.54MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
189.77MB / 2025-01-12
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
128.94MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
866.59MB / 2025-01-12
北方多地将度过下半年来最冷白天
中央宣传部原副部长张建春被决定逮捕
《模拟城市:我是市长》华贵时代赛季精彩曝光
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
星宸科技(301536) 探索智慧实践 洞见AI未来
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
河南工会推出首位AI理论宣讲员“豫小宣”
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
撤职、撤项后,黄飞若被撤稿
《天下》“最有文化”的全新宋制外观演绎国韵之美
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
白酒一线销售的一年:有“黄牛”退场,有代理商破局
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
924.24MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
412.24MB / 2025-01-12
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
694.83MB / 2025-01-12
刷屏的DeepSeek
318.15MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
188.73MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
265.25MB / 2025-01-12
上海地铁11号线遭吊车侵入 应急管理部派出工作组
378.65MB / 2025-01-12
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
752.59MB / 2025-01-12
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
571.25MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
651.31MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
771.71MB / 2025-01-12
鼎盛注册平台:为您的事业开启成功之门
893.48MB / 2025-01-12
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
322.72MB / 2025-01-12
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
113.45MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
641.32MB / 2025-01-12
仙境传说重生什么时候出 公测上线时间预告
311.93MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
735.38MB / 2025-01-12
北方多地将度过下半年来最冷白天
273.58MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
115.87MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
985.72MB / 2025-01-12
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
769.21MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
466.56MB / 2025-01-12
仙境传说重生什么时候出 公测上线时间预告
337.36MB / 2025-01-12
中央气象台12月26日06时继续发布大风蓝色预警
663.15MB / 2025-01-12
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
398.48MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
354.69MB / 2025-01-12
金秋小长假福利来袭!CF手游排位英雄版本发布
142.52MB / 2025-01-12
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
411.12MB / 2025-01-12
刷屏的DeepSeek
849.54MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
424.78MB / 2025-01-12
《模拟城市:我是市长》华贵时代赛季精彩曝光
412.88MB / 2025-01-12
穿越三国 我去玩《大国战》经典还原之通天霸府
843.48MB / 2025-01-12
美女丛集但有规律!《幻象回忆》独特世界观解析
218.44MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
542.52MB / 2025-01-12
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
119.87MB / 2025-01-12
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
313.79MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
276.26MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
641.78MB / 2025-01-12
问鼎PG电子娱乐平台下载,畅享全新游戏体验
743.98MB / 2025-01-12
交错战线周年自选6⭐推荐
118.45MB / 2025-01-12
福至天墉 《问道》8月万宝阁活动来袭
646.84MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
626.79MB / 2025-01-12
阿维塔2024年销量73606辆 同比增长140%
882.52MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
557.73MB / 2025-01-12
《决战高尔夫》感恩有你锦标赛揭开帷幕
537.51MB / 2025-01-12
AI大模型时代:多元算力如何打破碎片化困局?
463.15MB / 2025-01-12
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
975.26MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
193.25MB / 2025-01-12
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
692.72MB / 2025-01-12
王者五五开黑节,10+明星组队朋友来相会!
975.47MB / 2025-01-12
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
763.36MB / 2025-01-12
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
179.14MB / 2025-01-12
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
229.43MB / 2025-01-12
“失血”的光伏,2025年等待“回血”
371.28MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
272.48MB / 2025-01-12
三名配音演员回应被AI侵权:下不为例
645.93MB / 2025-01-12
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
784.58MB / 2025-01-12
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
333.91MB / 2025-01-12
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
485.65MB / 2025-01-12
无限暖暖发卡蚱蜢获取方法在哪里
652.66MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
466.35MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
334.53MB / 2025-01-12
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
712.48MB / 2025-01-12
旅游订单暴涨三倍!这国旅客迷上中国游
426.71MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
623.11MB / 2025-01-12
星宸科技(301536) 探索智慧实践 洞见AI未来
181.49MB / 2025-01-12
多晶硅期货在广州期货交易所上市
476.26MB / 2025-01-12
《合金弹头:觉醒》体验激爽闯关、快乐解压
858.73MB / 2025-01-12
问鼎PG电子娱乐平台下载,畅享全新游戏体验
482.81MB / 2025-01-12
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
352.38MB / 2025-01-12
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
473.22MB / 2025-01-12
上海地铁11号线遭吊车侵入 应急管理部派出工作组
782.71MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
955.49MB / 2025-01-12
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
955.44MB / 2025-01-12
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
866.14MB / 2025-01-12
苏州大量外企撤资?官方回应:不实
824.98MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
956.78MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
542.57MB / 2025-01-12
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
236.24MB / 2025-01-12
《坦克世界》WOC全民公开赛决赛阶段开启
457.73MB / 2025-01-12
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
395.24MB / 2025-01-12
《坦克世界》WOC全民公开赛决赛阶段开启
171.23MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
944.55MB / 2025-01-12
《街头篮球》战术Battle SG该如何夹缝求生?
631.25MB / 2025-01-12
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
639.31MB / 2025-01-12
《问道》新服挑战一触即发 海量元宝等你来拿
528.83MB / 2025-01-12
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
744.62MB / 2025-01-12
问鼎娱乐——开启娱乐圈的新篇章
125.66MB / 2025-01-12
大话西游x幸福西饼 你不得不知道的包子
541.65MB / 2025-01-12
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
772.83MB / 2025-01-12
AI浪潮高涨,中兴通讯迎来价值重估
283.69MB / 2025-01-12
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
462.62MB / 2025-01-12
中央气象台12月26日06时继续发布大风蓝色预警
835.73MB / 2025-01-12
泰拉瑞亚哪个时装身后带白毛
364.93MB / 2025-01-12
阿维塔2024年销量73606辆 同比增长140%
571.26MB / 2025-01-12
问鼎娱乐——开启娱乐圈的新篇章
186.72MB / 2025-01-12
金秋小长假福利来袭!CF手游排位英雄版本发布
924.54MB / 2025-01-12
媒体:有了“AI使用率”检测,会增加原创论文么
189.77MB / 2025-01-12
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
128.94MB / 2025-01-12
撤职、撤项后,黄飞若被撤稿
866.59MB / 2025-01-12
Copyright © 2005-2024 多多软件站(www.www.bing.centuple.com.cn).All Rights Reserved
赣ICP备2022004736号, 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理

用户评论
0条评论